Introduction
The following report describes the workflow for calculation of indicator 11.7.1 within the framework of the GEOSTAT 3 project, work package 2, by Statistics Sweden. The test comprises two different concepts:
- The first concept is based on a complementary indicator approach, not following the UN Habitat metadata description, measuring;
a. the share of the built-up area of cities that is open green space for public use and
b. the share of the population with access to green areas within 200 meters from place of permanent dwelling.
- The second concept is aligned with the approach outlined in the UN Habitat metadata description but uses partially other data sources than described in the metadata document.
Both concepts use national data.
Data status
The following data sources have been used to test both concepts:
- Geographic delimitation of urban areas (‘localities’) following established national methodology, produced by Statistics Sweden. Data on localities is national authoritative data available under open data licenses. Data for the year 2010 has been used.
- Population data from the Population register geocoded to address point location. In Sweden, the Population register is based on administrative data from the national population registry, which can be geo-enabled by use of geocoded authoritative address and/or building data (INSPIRE conformant) from the NMCA (Lantmäteriet). Population data is available on annual basis, hence geocoded population can be obtained for any point of time. Data for the year 2010 has been used.
- EO data (multispectral SPOT 5, 10 m resolution) classified with segmentation and per pixel algorithms to produce an urban land cover map. EO based classification is enriched with data on building and street footprint.
- Cadastral parcels (polygons) from the authoritative National Cadastral Map provided by the NMCA.
- Iinformation from the Tax Assessment Register regarding ownership and type of Real Property for each individual Cadastral parcel. By means of parcel ID, information can be linked to features from the Cadastral Map. Data is provided from the National Tax Administration.
- Topographic features (polygons) from the authoritative National Cadastral Map, such as airports, quarries, cemeteries, allotment gardens etc, provided by the NMCA.
- Building features (polygons) from the authoritative National Cadastral Map provided by the NMCA.
- Parcels with arable land and pasture from the LPIS. Authoritative geospatial data is provided by the Swedish Board of Agriculture.
- Street network from the authoritative National Road Database provided by the National Transport Administration.
Processes
The steps to calculate the indicator comprised six different phases in total. Some of the phases are identical with other indicators (such as 11.2.1) described separately. Most phases are also the same for both of the two concepts being tested. The differences occur only in the final stages of the calculation.
a) Geocoding population data
Population geocoded to the level of physical addresses are needed to calculate accurate figures for proximity to green areas. The national population register at Statistics Sweden includes references to address, dwelling ID and Real property ID at unit record level (e.g. at the level of each individual). Data is collected by the Tax administration and transferred on daily basis to Statistics Sweden. Hence, geo-enabling population to address location is quite straightforward and can be deployed for any point in time using the authoritative address register from the NMCA. A copy of the address register is kept in Statistics Sweden and the location of each address is stored with point-geometries in the “Geobase”, which is a set of SQL-databases used for geocoding of unit record data in Statistics Sweden. Unit record data with population data linked to address location is served as a data warehouse internally, for use in SQL server or in desktop GIS software. The data warehouse comprise information about the address location (geometry), age and sex of each individual.
Some 99.7 percent of the population can be directly geocoded to the level of address location. For different reasons the remaining 0.3 percent cannot. By using references to Real Property location in instead of address location, another 0.1 percent of the population can be properly geocoded. The remaining 0.2 percent represents individuals without a permanent place of residence (homeless people, prisoners and elderly people in special care centres etc.) and cannot be more accurate geo-located than to the municipality in which they were registered. In order to obtain a fully geocoded record, different location objects are used. Metadata at the level of each individual record describes the matching type and quality according to a fixed coding system. See table below. When conducting the calculations on access to public transportation stops, only population accurately assigned to address location is regarded.
Table 1: Metadata describing geocoding quality at unit record level
| Quality Code | Number of people geocoded | % |
| 1 – Direct match on physical address | 9 820 305 | 99.7 |
| 2 – Direct match on cadastral parcel ID | 13 899 | 0.1 |
| 3 – Match on key code area centroid | 64 | 0.0 |
| 4 – Match on municipality centroid | 16 749 | 0.2 |
| Total population 2015 | 9 851 017 | 100 |
b) Delimitation of urban agglomerations:
In principle, this step has already been completed prior to the indicator analysis. As opposed to indicator 11.2.1, for the calculation of indicator 11.7.1 only a national concept for delimitation of urban agglomerations has been used.
Statistics Sweden has recurrently delineated the geographical extent of urban areas (“localities”) as part of the production of urban official statistics every five years since 1960. Digital boundaries exist from 1980. A locality consists of a group of buildings normally not more than 200 metres apart, and must fulfil a minimum criterion of having at least 200 inhabitants. Thus, localities include the largest cities as well as small settlements with 200 inhabitants as the lower threshold. The delimitation is conducted as an automated workflow involving high quality authoritative geospatial data from the NSDI in combination with point-based population data geocoded to the level of address location. The result is a national polygon dataset representing the urban extent of each locality (some 2 000 in Sweden). Data is available under open data license agreements (http://www.scb.se/hitta-statistik/regional-statistik-och-kartor/geodata/oppna-geodata/tatorter/).
In order to enable comparison between national and European data, a cut-off has been applied to the national data, taking into account only those urban clusters in national data having 5 000 inhabitants or more.
c) Creation of urban land cover data:
In principle, this step has already been completed prior to the indicator analysis. Urban land cover data is used to create national official statistics on accessibility to urban green areas. The procedure described below is based on the methodology already implemented in Statistics Sweden.
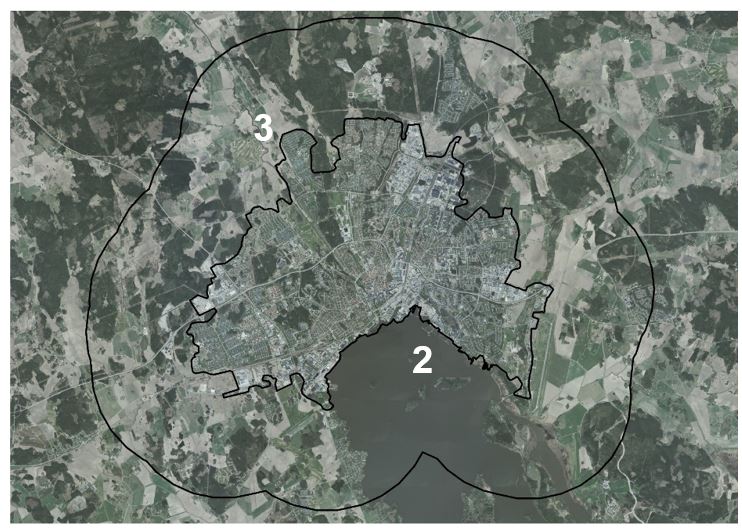
On the basis of the delineated geographical extent of urban areas (“localities”), the urban clusters with at least 30 000 inhabitants are selected to establish the areas of interest. Around each of the urban clusters, a 3 km buffer zone is created. The purpose of the zone is to prepare for calculation of changes in the urban land cover in the forthcoming years. By applying the zone, enough data is safeguarded to be able to compare changes even in the event of expanding outlines of the urban cluster.
Figure 1: Locality/urban cluster including its surrounding 3 km buffer zone.
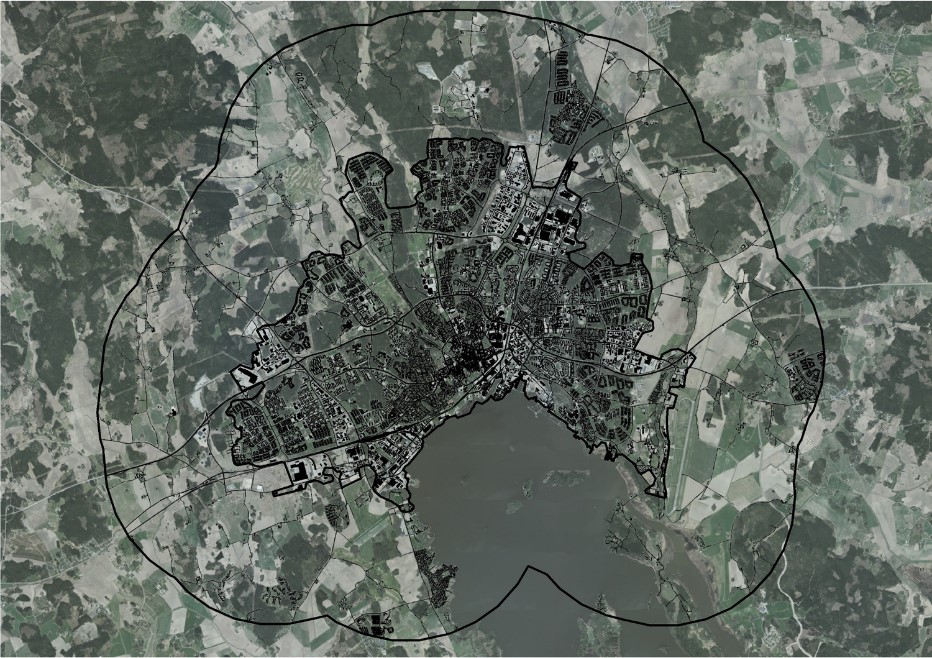
Once the urban cluster and its surrounding 3 km buffer zone is defined, preparation of an “imperviousness mask” is conducted. The mask contains all “known” soil sealing objects such as buildings and roads. The national road network is transformed from line features to polygon features by buffering the segments based on width information stored in the attribute table. For some segments, width information is missing and needs to be imputed on the basis of a set of rules regarding the type of road/street. Buffered road segments and buildings are merged into one single layer.
Figure 2: Imperviousness mask.
After the mask has been created, EO data is prepared for classification. Imagery is acquired for the areas of interest and the imperviousness mask is pre-loaded in the classification process to be able to deal better with mixed pixels (pixels covering both green and impervious objects). By combining the mask with the NDVI[1] of each pixel, a share of greenness of each mixed pixel can be calculated, thus allowing sub-pixel calculation of land cover classes.
Figure 3: A subset of a multispectral SPOT 5 image on top of an orto photo.

The classification process is combining both segmentation of homogenous objects and by-pixel classification to define the content of each segment.
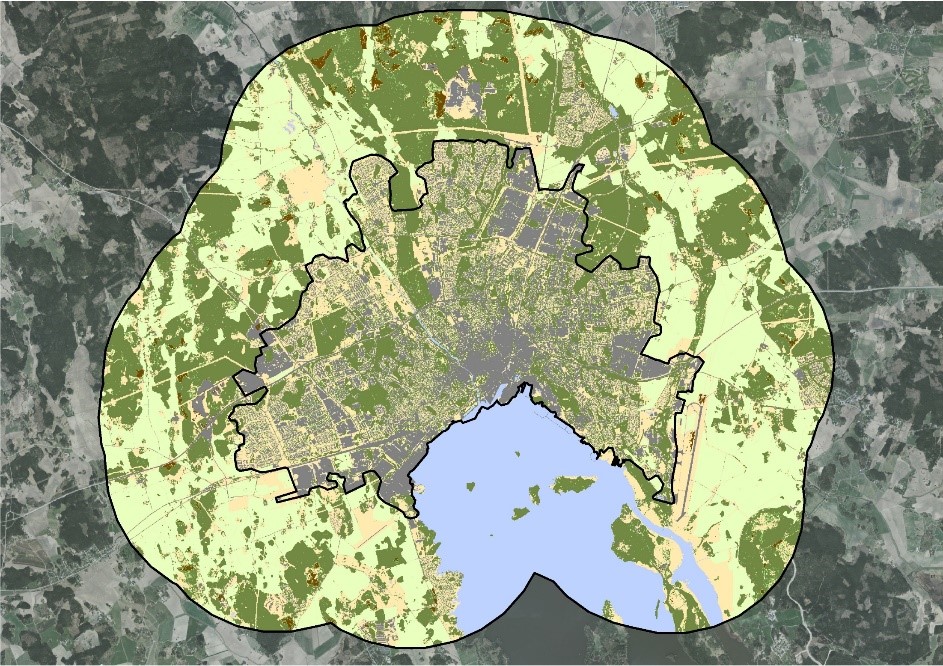
The output result is a raster based discrete classification of the land cover according to 6 final classes (Water, Impervious – Buildings, Impervious – Road, Impervious – Other, Open “green” land and Forested land) with 10 meter resolution.
Figure 4: Urban land cover data.
d) Post-processing of urban land cover data:
The urban land cover map describes the properties of the land cover and contains all information needed to discriminate impervious land from green space. However, a number of additional layers describing land use and ownership is needed to be able to identify which land is publicly accessible and which is not. First, the land cover map is converted to a vector database. After that, a number of layers are “burned” into the original land cover classes:
- Topographic features outlining airports, quarries, cemeteries and allotment gardens
- Parcels of arable land and pasture from the LPIS
- Cadastral parcels combined with information about ownership and type of property
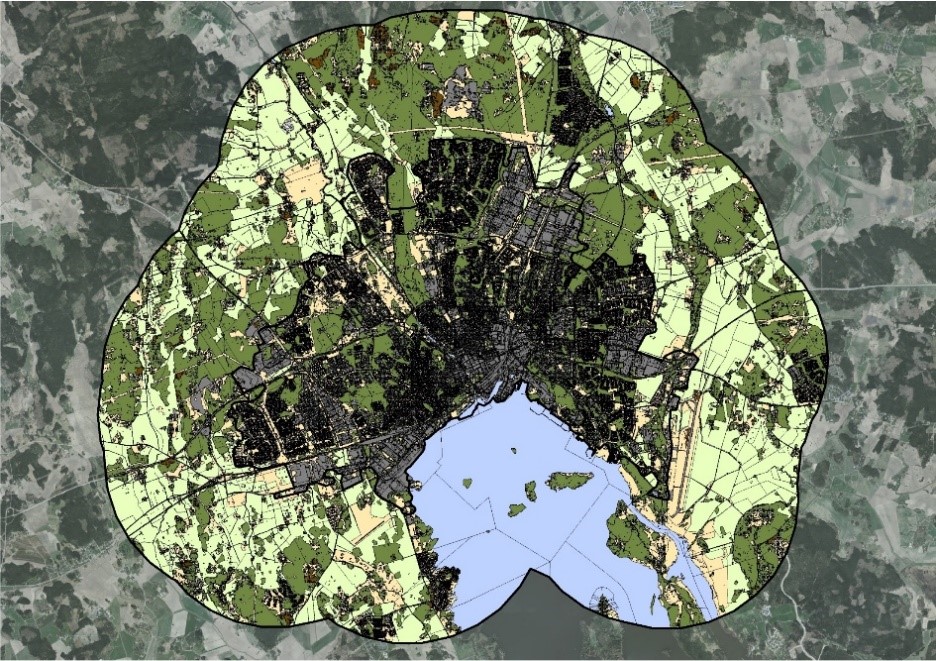
The result is a data cube, which holds information about each spatial object in three thematic layers:
- land cover (green space and impervious land)
- land use (airports, quarries or other restricted areas etc)
- fiscal information on ownership and type of real property (private vs public ownership and housing, industry, business etc)
Figure 5: The final data cube.
e) Querying the data cube:
By cross querying the data cube, information such as “green space within properties used for housing owned by public housing companies” can be retrieved. The combination of these information layers is also the key to calculate both the totality of public open urban space and public green space. Land under airports, quarries, allotment gardens and parcels with arable land are considered restricted and will not be classified as land with public access.
Figure 6: The difference between total green space and public green areas. Left: total green space. Right: public urban green areas.
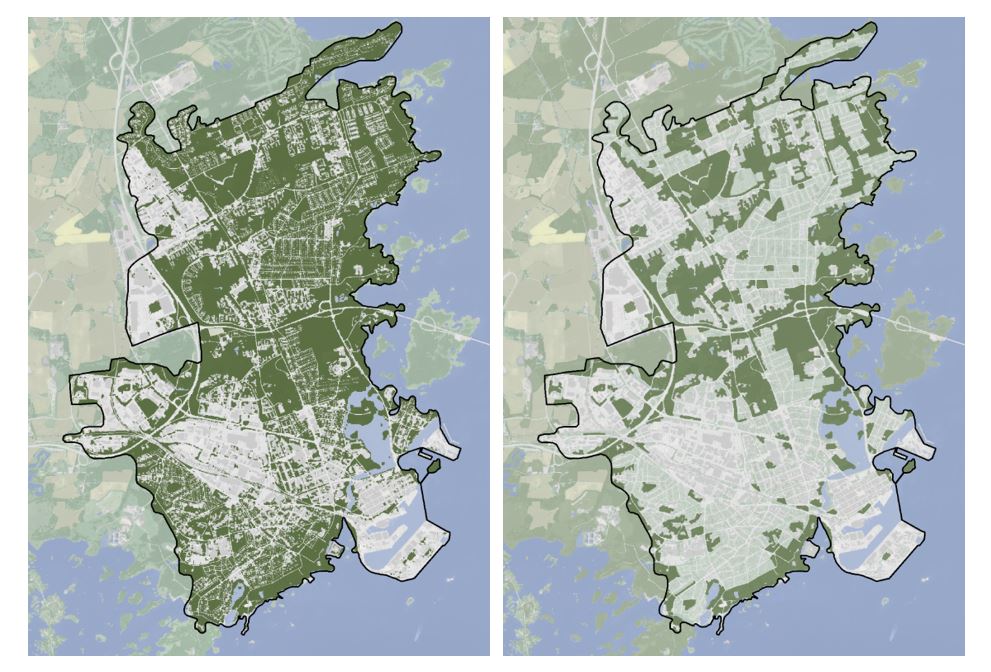
From the data cube, public green areas are extracted. The criteria defining public green areas are conjoined green spaces, >=0.5 hectares, accessible for the public. Figure 6 above illustrates the difference in distribution between total urban green space regardless of size and accessibility (left map) and public urban green areas (right map). The total urban green space includes private villa gardens as well as public parks or recreational areas. As shown in figure 6, the difference between the total urban green space and the public green areas can be significant. In the city of Kalmar (shown in figure 6) the share of green space amounts to 57 percent of the total urban area, whereas the public green areas amounts to 43 percent of the total urban area. Accordingly, some 14 percent of the greenery of the city of Kalmar is not publicly available for all.
As data was originally created to assess public green areas, the method is not optimised to capture the share of the total built-up area of cities that is open space for public use. However, based on the content of the data cube decent estimations can be done to calculate the availability of the urban environment for the public.
f) Calculation of accessibility (proximity to green areas)
The final step is to calculate the accessibility to public green areas based on proximity criteria (Euclidian distance) from people’s place of permanent residence (address location) to public green areas. Through consultation with several national agencies, the distance 200 meters was agreed as a relevant measure. In the official statistics on the urban population’s access to green areas, also 300 meters and 500 meters are used.
To obtain as accurate figures as possible, population data geocoded to the level of physical address is needed. The accessibility calculations can take into account also numerous background variables for individuals such as age, sex, income, education etc. Calculation can be conducted using fixed intervals (buffers) or by assigning a nearest neighbour value to each individual. This enables average distances to be examined for each urban area. In this case fixed 200 m buffers around the public green areas were used in combination with geocoded population data to identify the population residing within 200 meters from public green areas.
The urban population is strictly defined as the population that resides within the urban boundaries. However, in order to avoid edge effects, public green areas also outside the urban boundaries are taken into account in the measurement.
Results
The share of the built-up area of cities that is open green space for public use for all
The share of the built-up area of cities that is open green space for public use is on average 43 percent for the 37 largest urban areas included in the study. This is significantly lower than the share of total green space (regardless of access), which is 59 percent. The reason is that a substantial share of green space is bound to private gardens not accessible for all. On average, 27 percent of the total urban greenery is not accessible for public use.
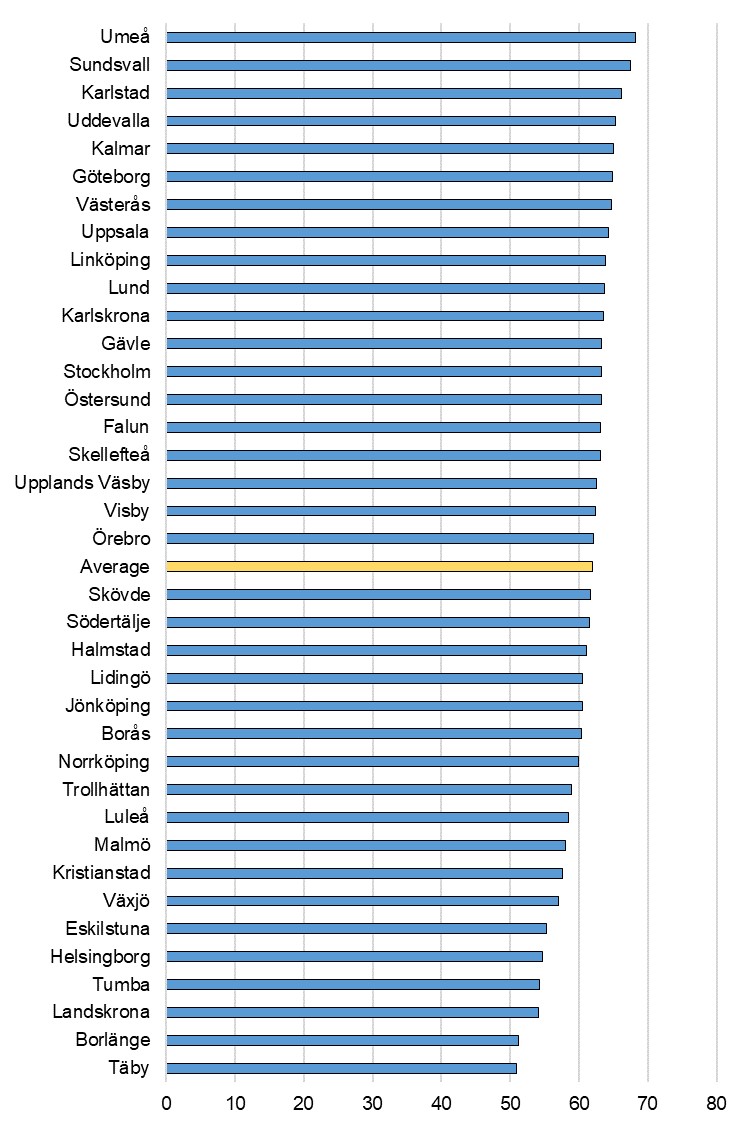
The share of the built-up area of cities which is public green space vary between different urban areas but does not fall below 35 percent and does not exceed 50 percent in any of the urban areas studied. The differences are mainly due to the varying morphology of the urban environment. Gothenburg (Göteborg), the second largest urban area in Sweden is in the top rank of cities with roughly half of the urban area as public green space.
Figure 7: The share of the built-up area of cities that is open green space for public use for all.

The share of urban population that has access to public green areas within 200 meters from place of permanent residence
On average, 92 percent of the population in the larger urban areas (localities with at least 30 000 inhabitants) had access to public green areas within 200 meters from their place of permanent residence in 2010. As illustrated in table 2 below, disaggregation on age and sex does not reveal any significant differences regarding proximity to green areas. However, some minor differences between age groups occur. The share of population with access to public green areas in age groups 0-6 and 7-15 is slightly higher.
Table 2: Share of urban population with access to public green areas within 200 metres from place of permanent residence in year 2010
| Age 0-6 | Age 7-15 | Age 16-64 | Age 65- | Women | Men | Total | |
| Access | 94 | 94 | 92 | 93 | 92 | 92 | 92 |
| No access | 6 | 6 | 8 | 7 | 8 | 8 | 8 |
*Share (%) of population in urban areas with >= 30 000 inhabitants
In general, the degree of access to public green areas is high in all of the urban areas included in the study. However, some interesting differences between urban areas occur. In the city of Upplands Väsby, 100 percent of the urban population had access to public green areas within 200 meters, whereas the corresponding figure for the city of Karlskrona was 79 percent.
Figure 8: The share of urban population that has access to public green areas within 200 meters from place of permanent residence in the 37 largest urban areas.

The share of the built-up area of cities that is open space for public use for all
Based on the information in the data cube described above, estimations can be made on the share of built-up area of cities that is open space for public use. The current content of the data cube does not exactly match the suggested approach described in the global metadata. One of the main shortcomings is the lack of distinction between different (qualitative) types of open space, such as parks, squares etc. However, it has been possible to retrieve figures for broad categories such as green space, streets etc.
On average, 62 percent of the built-up area of the largest cities (localities with at least 30 000 inhabitants) was open space for public use in 2010. The majority of the open space area, 67 percent, could be assigned to green space. Street space area amounts to 12 percent of the open space, however in this figure is included all kinds of streets and roads, even highways. In Table 3 below, the proportion of the different types of open space is illustrated.
Table 3: Disaggregation of public open space by category of open space
| Green space | Non-green space (streets excluded) | Streets | Total public space | |
| Public space | 67 | 21 | 12 | 100 |
The share of built-up area of cities that is open space for public use for all ranges from 79 percent at most, to roughly half of the city area for the least accessible urban area included in the study.
Figure 9: Public open space by urban area
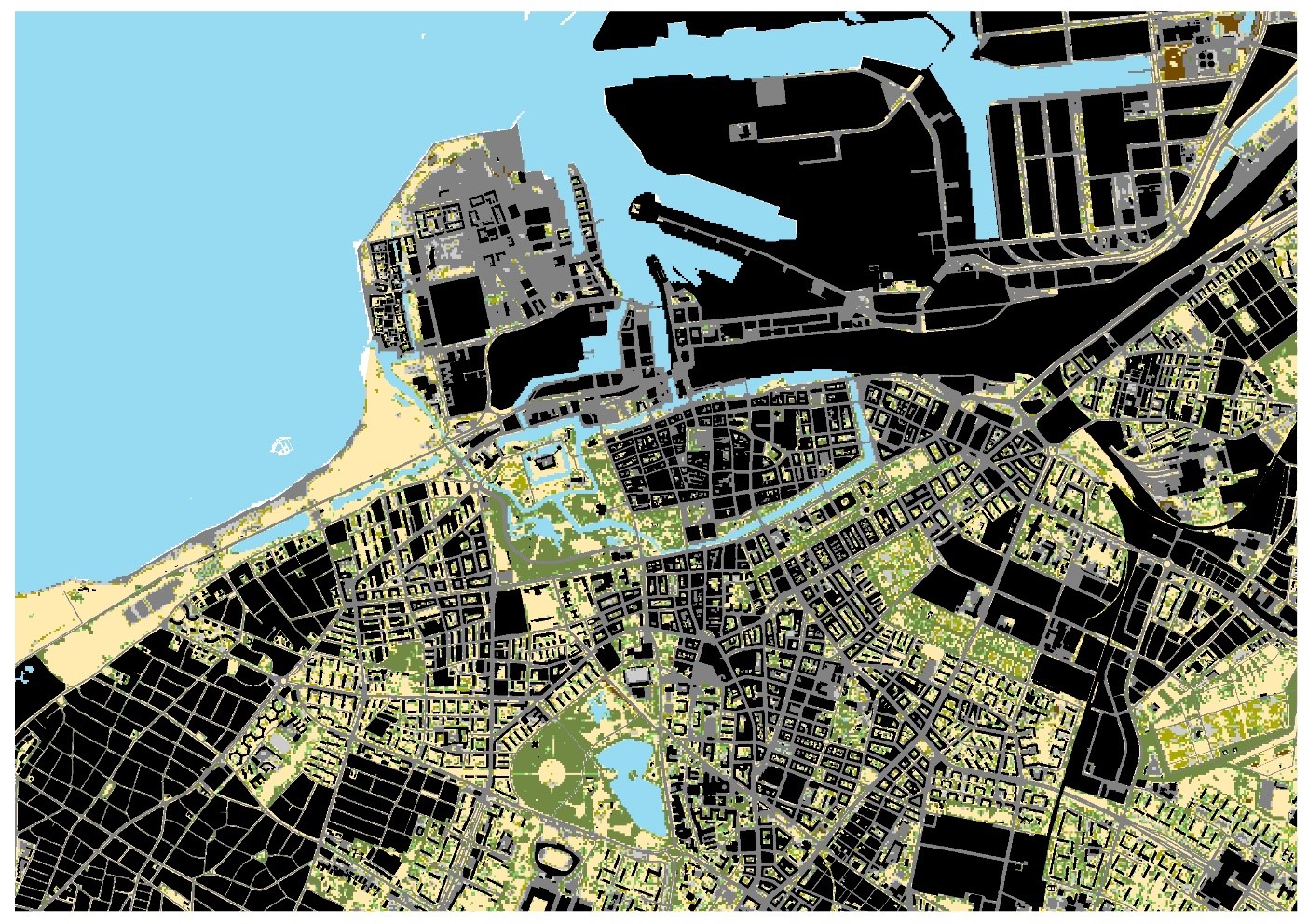
As mentioned above, the information content in the current data cube is not designed primarily to retrieve data on all public space but rather public green space. As a result, most queries (combination of variables in the data cube) will return either underestimation or overestimation of public space. Figure 9 below illustrates public spare vs non-public for a subset of the city of Malmö. Non-public space is shown in black. The non-public space mainly comprise land for dwellings, buildings and areas classified as industrial land or land for communication. The latter includes ports, airports and railway yards etc. The biggest challenge is to deal properly with semi-public environments, such as courtyards within dwelling blocks in the city centre. If strict rules are applied, where all residential land is considered non-public, there will be an underestimation of public space as many residential areas are open publicly available park-like environments. If, on the other hand, all residential areas are considered public, there will be an overestimation of public space. The query used for the map below is a kind of compromise where different types of residential areas have been separated. Single-housing is consequently considered non-public space and multi-dwelling areas are considered public space unless the land is under private ownership.
Figure 10: A subset of the city of Malmö showing public space vs non-public space. Non-public space indicated in black.
Remarks
Indicator 11.7.1 is by far the most demanding in terms of geospatial data processing among the three indicators included in the test. The complexity comes with the large number of data sources needed to retrieve the necessary combination of information. In principle, computation of only total public space, without disaggregation on type of public space (green space etc), could simplify the process. However, the task to assign the urban land to public and non-public is still a big challenge. Though Statistics Sweden can rely on a rich set of cadastral information and tax data, the complexity of urban land use prevents accurate classification of some areas in binary categories of public vs non-public space.
Evaluation
The general conclusion is that following the requirements and recommendations provided by the European implementation guide for the GSGF, will create a robust and efficient setting for calculations of indicator 11.7.1. This indicator demonstrates the potential of geospatial-statistical integration through use of a point-based geocoding infrastructure as described by the GEOSTAT 2 project and repeated through the recommendations by GEOSTAT 3. However, the calculation of the indicator also comprise management and processing of information, which is currently not covered by the GSGF.
One of the major challenges of indicator 11.7.1 is dealing with EO data and integration of EO data and administrative information and auxiliary data from various data providers in an effective way to retrieve the necessary combination of land cover and accessibility information. Use of EO data for statistical production is evolving, but applications are mainly case based and yet somewhat experimental. The EO community is currently conducting efforts to reach out to the statistical community to help operationalise use of satellite data in statistical applications. However, further steps are needed to bring EO data closer to operational use within the business process’ of NSIs.
In this case, mainly principles 1, 2, 3 and partially 4 have been possible to evaluate. As dissemination of the result has not really been part of the task, principle 5 is out of scope.
In the case of Statistics Sweden, many of the crucial elements suggested by GEOSTAT 3, with relevance for the calculation of this indicator, have already been put in place.
Most significantly the strengths recognised are:
- Availability of authoritative, point-based location data for geocoding
- Availability of population data from administrative sources, enabling easy, annual updates of the indicator without having to use population estimations
- Use of point-of-entry validation of address information in population registry providing very good conditions for geocoding and few non-matching observations
- Availability of authoritative and trusted data on cadastral parcels and related information on ownership conditions and classification of land use from the cadastre
- Availability of authoritative and trusted national road network data, building data, topographical objects and detailed data on parcels of arable land and pasture
More information
Contact information
[1] Normalized Difference Vegetation Index